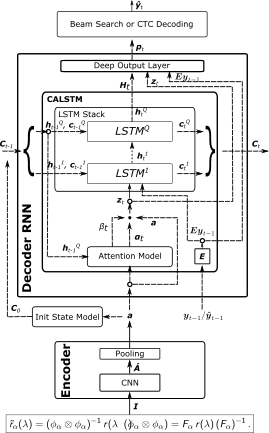
Abstract
We present a neural transducer model with visual attention that learns to generate LATEX markup of a real-world math formula given its image. Applying sequence modeling and transduction techniques that have been very successful across modalities such as natural language, image, handwriting, speech and audio; we construct an image-to-markup model that learns to produce syntactically and semantically correct LATEX markup code over 150 words long. We achieve a BLEU score of 89%, a new state-of-art for the Im2Latex problem. We also demonstrate with heat-map visualization how attention helps in interpreting the model and can pinpoint (localize) symbols on the image accurately despite having been trained without any bounding box data.
Test Results
Two model variations are presented:
-
I2L-NOPOOL -
I2L-STRIPS
- Random Sample of Predictions
- Correct Predictions
- Incorrect Predictions (Mistakes)
- Attention Scan Visualization
- Model Training Charts
Attention Scan Visualization (Both Models):
Datasets
Formula Lists
Text file with normalized LaTeX formulas. Get this if you want to generate your own dataset starting with normalized formulas. You would copy this file into file the folder named ‘step0’ (see the preprocessing notebooks for details).
I2L-140K dataset is recommended over Im2latex-90k since it is the larger of the two (and a superset of Im2latex-90K), and yields better generalization.
Full Dataset
All preprocessed data: i.e. all images as well as DataFrames and numpy arrays produced at the end of the data processing pipeline.
Model Weights
Model checkpoints of the two GPU version can be downloaded here. You will need to extract the weights if you are training on a different number of GPUs. Test-run args and hyperparameters are in args.pkl and hyper.pkl files and also printed to traning.log.
Hardware
We used two NVIDIA GeForce 1080Ti Graphics Cards